High-Performance Text Analysis with HuggingFace GPT-2 on AWS Neuron with AWS Inferentia
Welcome to QA’s lesson where you’ll learn how to utilize the AWS deep learning AMI with the Neuron SDK and PyTorch on AWS Inferentia to compile and execute the HuggingFace GPT-2 model.
This model, built within the PyTorch framework, excels in generating relevant and coherent text. You’ll see how feature extraction on Inf2 instances, powered by AWS Inferentia, accelerates deep learning inference with greater speed and efficiency compared to traditional CPU and GPU setups.
By the end of this lesson, you will have an understanding of how to:
- Request a service quota increase to launch Inferentia instances
- Launch an AWS Deep Learning AMI on an Inf2 instance
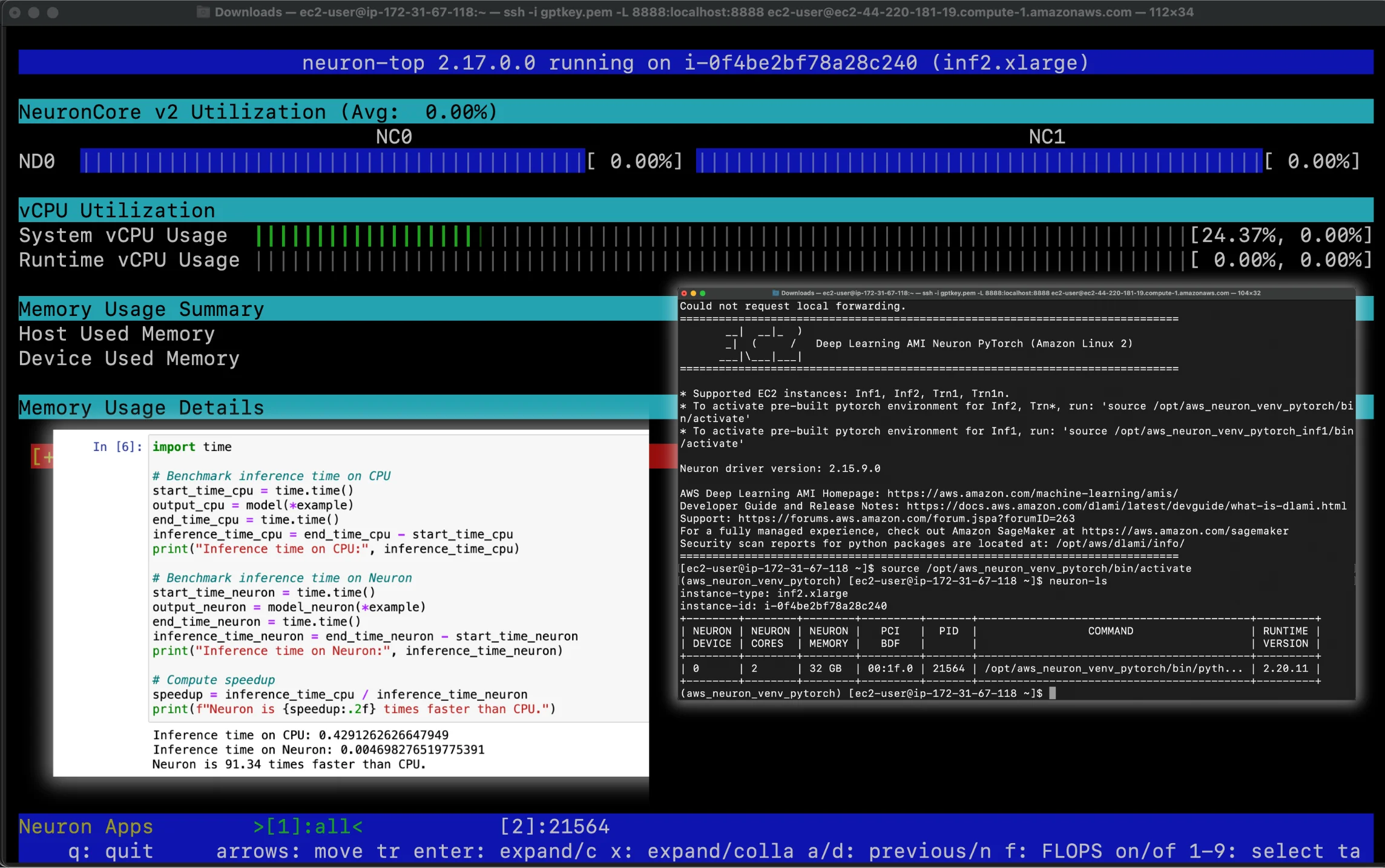
- Establish a secure SSH connection to the Inf2 instance
- Activate the Neuron environment, verify installation of key packages, and run Neuron tool commands
- Establish SSH tunneling for secure Jupyter Notebook access
- Launch and configure a Jupyter Notebook environment
- Optimize and deploy HuggingFace GPT-2 model on AWS Inf2 instances
- Conduct performance tests to compare inference times between CPU and Neuron-powered GPU instances
GitHub Repository
To access the Python scripts and commands for compiling and executing the HuggingFace GPT-2 model, along with additional materials for this lesson, please visit our GitHub repository here:
Intended Audience
This lesson has been created for data scientists, machine learning engineers, and developers with basic knowledge of machine learning.
Prerequisites
To get the most out of this lesson you should have a familiarity with basic machine learning terms.
Get Started
High-Performance Text Analysis with HuggingFace GPT-2 on AWS Neuron with AWS Inferentia